Hive vs Presto: Complete Comparison for Big Data Query Engines (2026 Guide)
Table of Contents
- Introduction to Hive vs Presto
- What is Apache Hive?
- 2.1 Key Features of Hive
- What is Apache Presto?
- What is Hive Used For?
- What is Presto Used For?
- Hive vs Presto: Key Differences
- When to Choose Hive vs Presto
- Using Hive and Presto Together
- Deep Dive Analysis
- 9.1 Performance and Execution Model
- 9.2 Architecture and Data Connectivity
- Conclusion
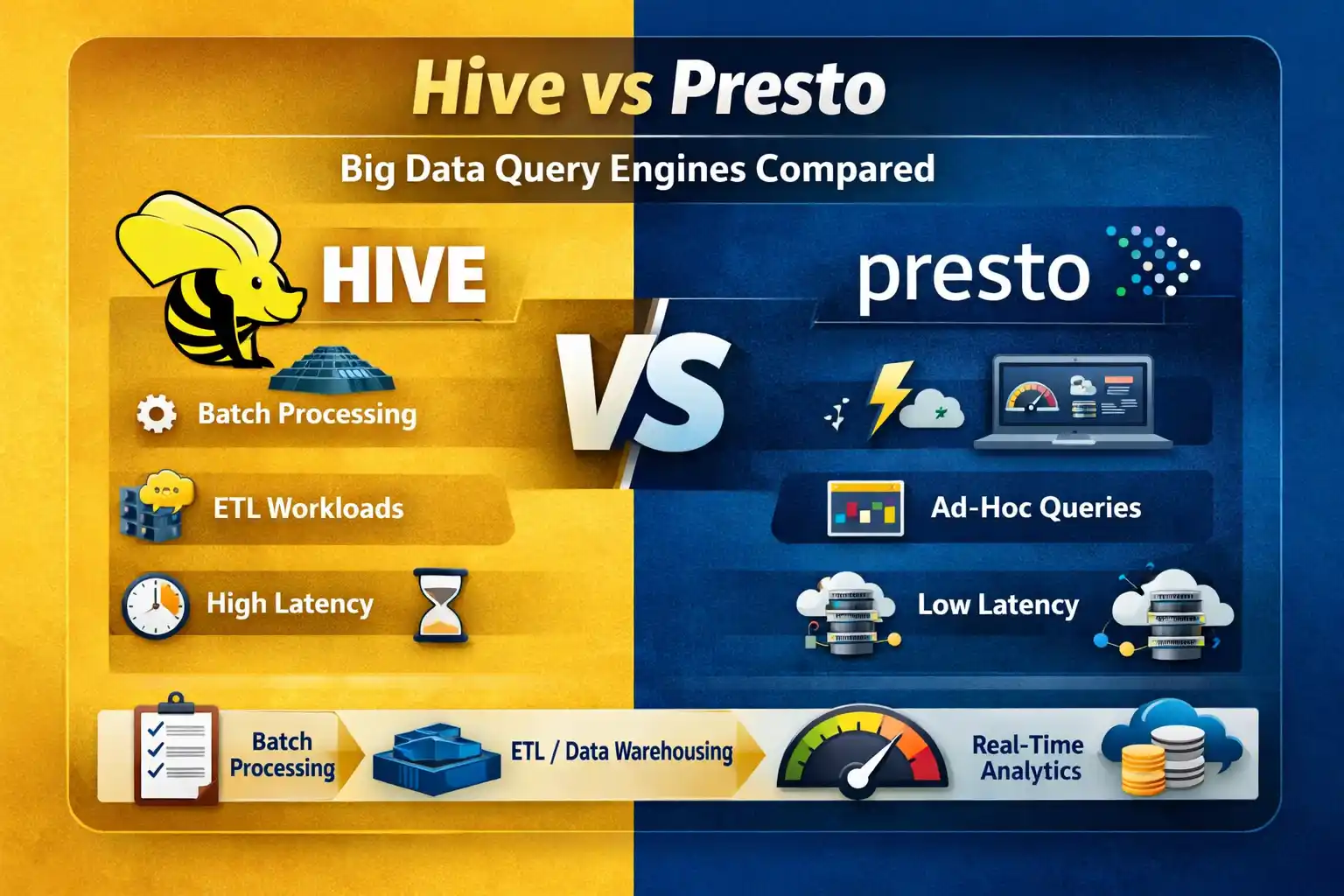
If you're working in the Big Data ecosystem, choosing the right query engine is critical for performance, scalability, and cost optimization. Two of the most widely used tools are Hive and Presto.
In this guide, we’ll break down Hive vs Presto, compare their features, use cases, performance, and help you decide which one is best for your data architecture.
What is Hive?
Apache Hive is a data warehouse system built on top of Hadoop. It allows users to query large datasets using SQL-like language called HiveQL.
Key Features of Hive:
- Designed for batch processing
- Uses MapReduce, Tez, or Spark as execution engines
- Suitable for ETL workflows
- Handles large-scale data processing
- Schema-on-read architecture
What is Apache Presto?
Apache Presto (also known as PrestoDB) is an open-source, distributed SQL query engine designed for fast, interactive analytics on large datasets. It allows you to run SQL queries across multiple data sources without needing to move or transform the data.
Key Features of presto:
- Blazing Fast Query Performance
Presto uses in-memory processing to deliver real-time query results, making it ideal for interactive analytics. - Query Multiple Data Sources
Easily connect and run SQL queries across HDFS, Amazon S3, MySQL, Kafka, and more—without moving data. - Supports Standard SQL (ANSI SQL)
No need to learn new syntax—Presto works with familiar SQL queries for quick adoption. - Highly Scalable Distributed Engine
Designed to scale across clusters, allowing efficient processing of massive datasets. - No Data Movement Required
Presto queries data directly from source systems, reducing data duplication and improving efficiency.
What is Hive used for?
The content explains that Hive is used for building data pipelines, processing huge datasets in batch mode, and is heavily integrated with the Hadoop ecosystem.
What is Presto used for?
The content outlines that Presto is used for real-time analytics, running ad-hoc SQL queries, building dashboards, and querying multiple data sources.
The choice depends on your use case:
- Choose Hive for batch processing and ETL pipelines
- Choose Presto for fast analytics and real-time querying
In modern architectures, companies often use both together:
- Hive for data storage & ETL
- Presto for querying and analytics
Deep Dive Analysis
- Presto is an in-memory distributed SQL engine that skips the overhead of writing intermediate results to disk, making it often 10x-100x faster than traditional Hive. It is engineered for interactive ad-hoc queries, returning results in seconds.
- Hive utilizes a disk-heavy execution model, which is slower but provides higher throughput for massive ETL jobs that take hours. However, modern Hive on Tez or Spark is much faster than the legacy MapReduce engine.
- Presto excels at federation. A single Presto query can join data from HDFS, S3, MySQL, and Kafka simultaneously without requiring data movement.
- Hive is natively integrated with Hadoop/HDFS and the Hive Metastore, making it superior for managing long-term data lakes where data is heavily partitioned and managed within the ecosystem.
Conclusion
The most efficient 2026 data architecture often combines both: Hive for the batch ingestion and heavy-duty ETL, and Presto for serving the prepared data for rapid, analytical querying.
About the Author
I am a Data Science Engineer specializing in Machine Learning, Generative AI, Cloud Computing, Hadoop, Scala, Java, and Python. With expertise in cutting-edge technologies, I share valuable insights, blogging tips, and tech tutorials on DeveloperIndian.com, helping developers and data enthusiasts stay ahead in the industry.